스프링 프로젝트 789번 이슈에 '왜 Lettuce가 기본으로 설정되었는가?'라는 질문이 있었습니다. 진행 중인 프로젝트에도 Lettuce를 사용하고 있는데 왜 이것을 사용해야 하는가를 고민하지 않고 '성능이 좋다'라는 이야기만 듣고 사용하고 있었죠. 왜 Lettuce가 Spring boot에서 기본으로 사용하고 Jedis와 어떤 차이가 있을까요?
1. Jedis, Not thread-safe, Synchronous
Jedis는 스레드 세이프하지 않습니다. 즉, 멀티 스레딩 환경에서는 문제가 발생할 수 있습니다. 그렇기 때문에 Jedis는 객체를 커넥션 1개와 캡슐화하여 pool로 관리합니다. 즉, (thread 1개 + 커넥션 1개) = Jedis 객체인 형태입니다.
현재 진행 중인 프로젝트에서는 WAS의 Scale-out 시 발생하는 세션 불일치 문제를 해결하기 위해서 '메모리 기반 외부 저장소'를 선택했습니다. 이를 통해서 응답 속도 개선과 세션 불일치 문제를 해결하고자 했습니다. 멀티 스레딩 환경에서는 이 문제가 해결이 된 것처럼 보이지만, 사실 또 다른 문제를 발생시킬 수가 있습니다.

1. WAS가 늘어날수록 요구하는 커넥션 풀의 사이즈가 커진다.
2. 만약 커넥션 풀이 부족할 경우 나머지 요청들은 전부 대기하게 된다.
3. 커넥션 풀 사이즈를 늘려도 결국 사용이 안 되는 커넥션이 존재할 것이다. 제한된 컴퓨팅 성능을 낭비하게 된다.
4. 동기적으로 동작하기 때문에 CPU을 최대한 사용할 수가 없다. (CPU가 항상 어느 정도의 idle 상태가 유지됨)
위 문제는 어떻게 해결할 수 있을까요?
2. Lettuce, Non-blocking I/O, Asynchronous
Lettuce는 스레드 세이프하며 netty 기반으로 비동기 Non-blocking으로 동작합니다. 이를 통해서 여러 멀티 스레드가 커넥션 인스턴스들을 공유할 수가 있습니다. 이를 통해서 '적은 커넥션으로 멀티 스레드 환경에서 동작', '스레드는 요청한 처리가 완료될 때까지 블록킹 X', 'CPU를 최대한 활용' 등의 이점을 얻을 수 있습니다.
그런데 여기서 한 가지 의문점이 있습니다. 자바도 결국 JVM에서 동작할 뿐이고 JVM도 메모리에 올라와 있는 프로세스 중 하나입니다. 이런 프로세스를 관리하는 것이 운영체제입니다. 자바가 아무리 마법을 부려도 운영체제에게 자원을 요청하지 않는다면 어느 것도 할 수 없습니다. Non-blocking은 어떻게 동작할 수 있을까요?
3. POSIX - Select()
비동기 I/O는 MacOS, Windows, Unix/Linux 마다 약간의 차이가 있지만 비슷한 방식으로 구동됩니다. 이 글에서는 POSIX - Select()를 기준으로 설명하겠습니다.
3.1 File Descriptor

'유닉스의 모든 것은 파일이다!'라는 말도 있습니다. Unix, Unix와 같은 운영체제는 I/O, pipe, socket, file, disk를 다룰 때 File Descriptor(FD)를 사용합니다. 하지만 FD도 하나의 '인덱스'입니다. 즉, FD를 통해서 'file table'이라는 곳을 가리키고 있습니다.
File table은 현재 파일의 mode와 같은 정보를 기록하고 있습니다. 여기서는 프로세스에 의해서 열린 모든 파일 상태를 관리하며 다시 Inode table를 가리킵니다. Inode table은 실제 파일이 파일 데이터가 있는 테이블입니다. 예를 들어 'test.txt'라는 파일이 있다면 그 안에 있는 '안녕하세요.\n(...)'가 실제로 있는 곳이죠. (장치, IO 등 모두 이런 식으로 관리가 됩니다.)
그렇다면 왜 이렇게 여러 단계로 나눠 관리할까요? 그 이유는 하나의 프로세스가 여러 개의 파일을 열 수도 있고, 접근하는 파일이 다른 프로세스가 처리해서 현재 파일에 대한 상태를 알 필요가 있습니다.
이렇게 여러 파일과 그곳에 접근하는 프로세스를 효과적으로 관리하기 위해서 위와 같은 구조로 설계가 되었다고 합니다.
3.2 Select() - IO Multiplexing
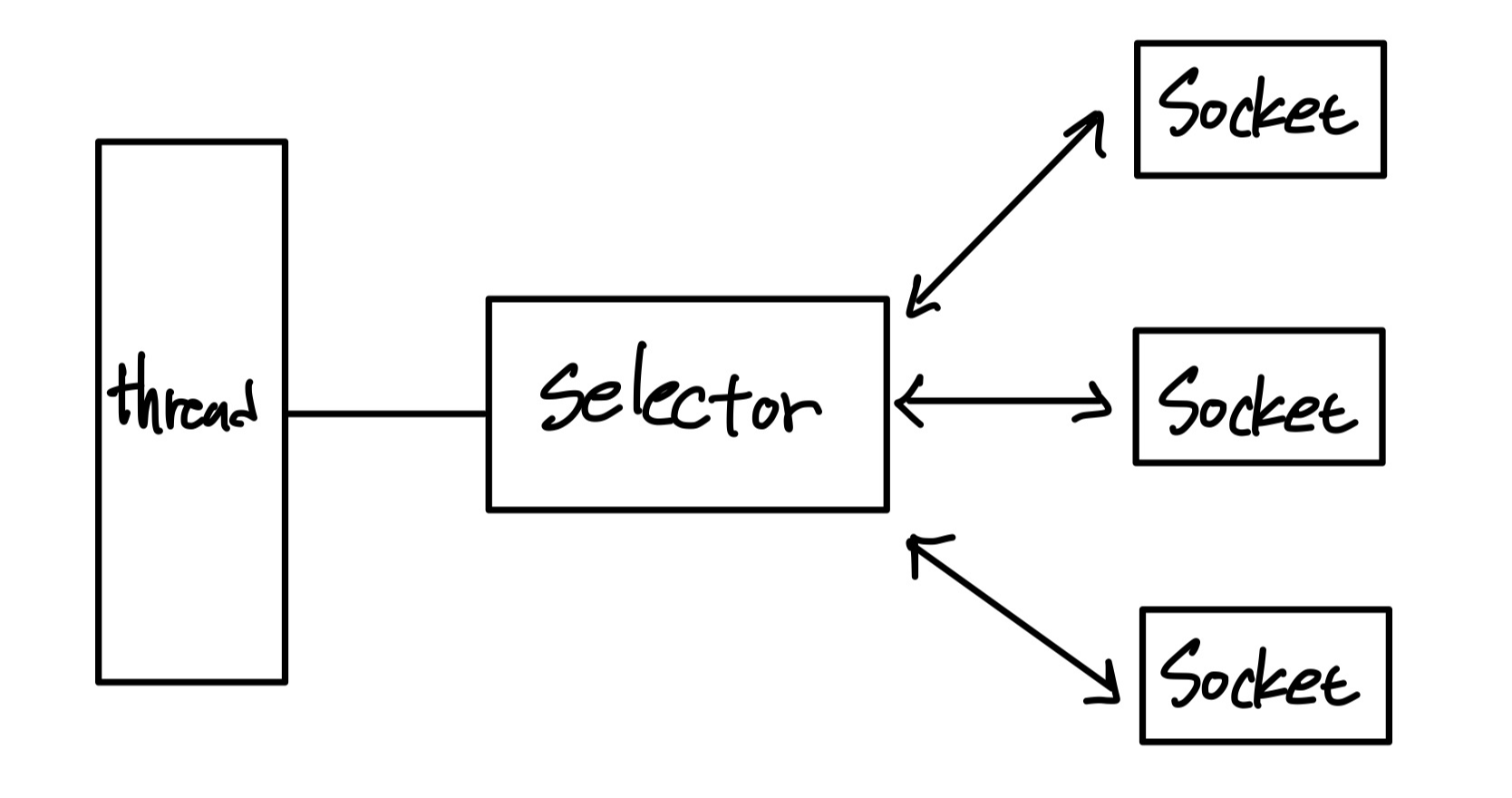
그렇다면 위 Redis에서 설명한 '스레드와 커넥션, 동기적으로 동작'과 'FD'를 함께 설명할 수가 있습니다. 즉, '하나의 프로세스가 하나의 FD를 가지는 구조'라고 할 수 있습니다. 당연히 IO가 발생하는 동안 대기할 수밖에 없습니다. 또한 요청에 따라 그만큼의 FD도 준비해야 합니다. 위 1번에서 등장한 문제와 매우 유사하다고 생각합니다. 하지만 이미 운영체제에서 이 문제를 '여러 FD 집합을 하나의 요청으로 관리하자'라는 아이디어가 나왔고 이것이 Select()입니다. (이후 poll, epoll로 발전했습니다.) 이렇게 '하나의 프로세스가 여러 개의 FD를 관리하는 방식을 IO Multiplexing'라고 합니다.
3.3 Netty와 무슨 관계가 있나?
이제 'Netty 기반, 비동기, Non-blocking'이라는 뜻이 좀 더 이해하기 쉬워집니다. '하나의 커넥션을 통해서 여러 스레드가 공유할 수 있다'라는 뜻은 결국 IO Multiplexing을 이용하는 '커넥션'을 여러 스레드가 공유하는 것이라고 해석할 수 있습니다.
참고자료
'프로젝트 > 끄적끄적' 카테고리의 다른 글
| 비동기 처리를 위한 transactional outbox pattern 적용 (0) | 2023.01.05 |
|---|---|
| Spring Batch 페이징 쿼리 성능 개선하기 (0) | 2023.01.04 |
| 비밀번호 해시 함수 고민과 선택 (0) | 2022.09.25 |
| Scale-Up과 Scale-Out 각 장단점은 무엇일까? (Session Storage, 세션 불일치) (0) | 2022.09.22 |



