진행한 프로젝트에서는 인증 메일 전송을 Spring Batch를 활용해서 구현했습니다. Spring Batch에서는 2개의 Reader를 제공하는데, Cursor와 Paging입니다.
Cursor는 데이터베이스와 커넥션을 맺은 후 Cursor를 옮겨가며 데이터를 조회합니다.
반면에 Paging은 페이지 단위로 데이터를 한 번에 조회해오는 방식입니다. limit과 offset을 pageSize에 맞게 자동으로 생성해서 전달해 줍니다. 사용자가 갑자기 몰릴 경우에 Cursor 방식보다 Paging 방식이 더 효율적인 구현이라 판단하고 Paging 방식을 선택하였습니다.
Paging방식으로 ItemReader 인터페이스를 구현한 다양한 구현체들이 있는데, 현 프로젝트에서 사용하는 것은 Mybatis이기 때문에 이를 활용해서 구현하고자 합니다.
1. MybatisPagingItemReader

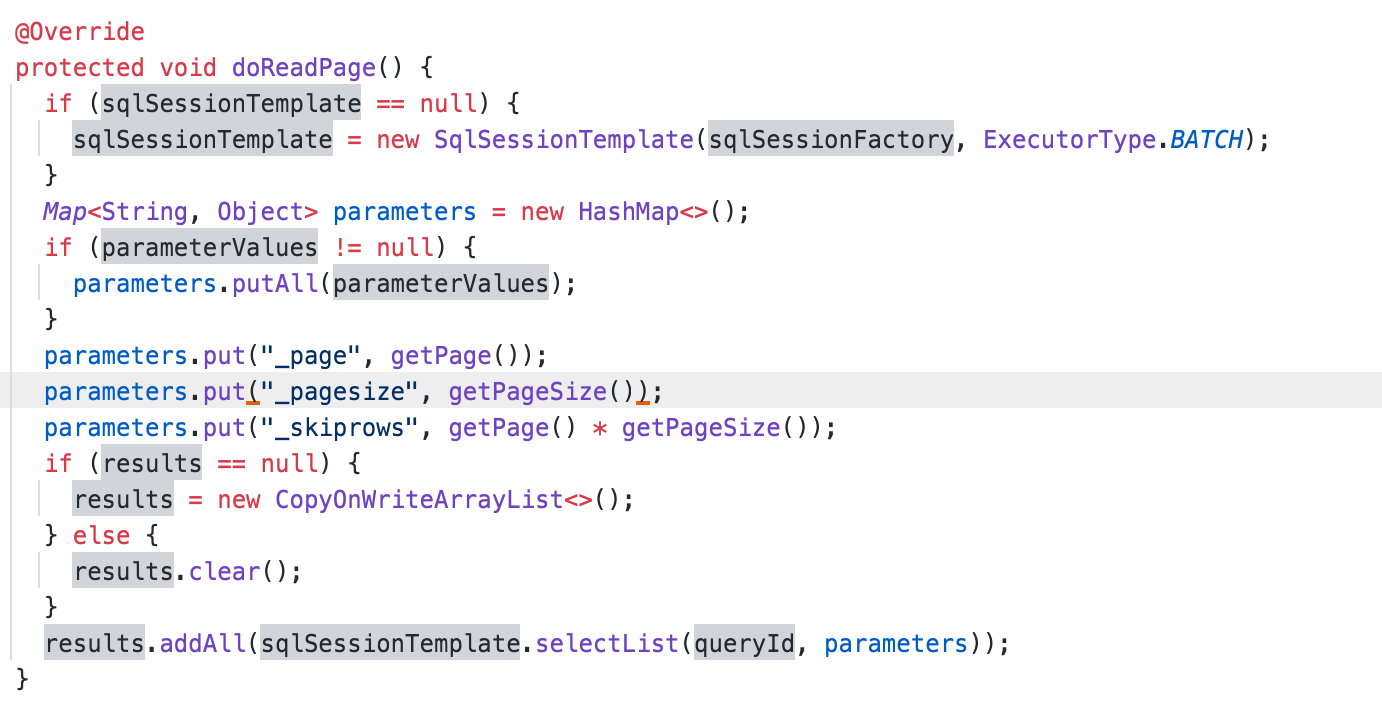
Mybatis 공식 문서에는 MybatisPagingItemReader에 대한 설명이 있습니다. 여기서 주목해야 할 것은 아래 맵핑할 select 문입니다.

현재 사용하는 데이터베이스는 MySQL 5.7이고, 인증 메일 전송 기능은 회원가입이 트랜잭션과 함께 이벤트 테이블에 저장하는 방식입니다.
@Bean
@StepScope
public MyBatisPagingItemReader<Event> MailSendingEventReader() {
MyBatisPagingItemReader<Event> pagingItemReader = new MyBatisPagingItemReaderBuilder<Event>()
.pageSize(100)
.sqlSessionFactory(sqlSessionFactory)
.queryId(QUERY_ID)
.build();
return pagingItemReader;
}IteamReader는 위 예시에 있는 쿼리를 기반으로 정해진 pageSize에 맞춰 데이터를 가져오게 됩니다. 예를 들어 '500부터 10개의 데이터를 가져올 때는 쿼리가 아래와 같이 실행이 될 것입니다.
SELECT id
FROM outbox
ORDER BY id
LIMIT 500, 10
하지만 사용자가 급격하게 몰리고 기존 사용자로 인해 생성된 이벤트가 많이 쌓여 있다면? 이는 쿼리 실행 속도에 영향을 주게 됩니다.
2. MySQL limit 동작 방식

MySQL limit는 오프셋 값만큼 레코드를 읽어온 뒤에 필요한 레코드 수를 제외하고 전부 버리는 방식으로 동작합니다. 즉, 5백만번 째의 레코드를 읽어야 할 경우, 이를 전부 읽은 다음에 필요한 수를 반환하고 나머지를 버리는 것입니다. 결국 사용자가 급격하게 증가하거나 기존 테이블에 데이터가 너무 많이 쌓여 있을 경우에 쿼리 실행 속도에 영향을 주게 됩니다.
느려지는 속도를 확인하기 위해서 Kaggle에서 1억 개의 데이터를 구해 조회 속도를 테스트해 보았습니다.


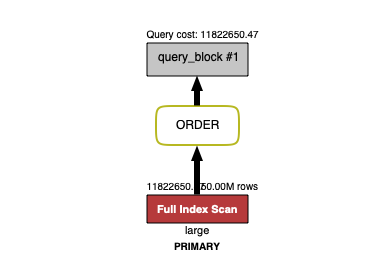

위 쿼리를 기반으로 5백만부터 100개를 조회하는 쿼리를 실행했을 때, 무려 23초(!)나 걸리는 것을 확인했습니다. 즉, 쿼리 1번 실행에 23초가 소요되는 것이고 이대로 방치할 경우 계속해서 느려질 것이 예상되었습니다.
3. 쿼리 개선하기 - No Offset 응용
이를 해결하기 위해서 여러 자료를 찾던 중에 'No Offset 사용하기'를 알게 되었습니다.
limit 방식의 문제는 '처음부터 끝까지 읽는다'입니다. 이것은 원하는 데이터의 PK 값만 빠르게 읽어서 조회하는 것으로 해결이 가능할 것입니다.
하지만 MybatisIteamReader는 offset 방식으로 페이지를 계산하기 때문에 '마지막으로 조회한 ID 값'을 알 수가 없었습니다. 그래서 Primary index로 빠르게 원하는 PK 값으로 접근한 뒤, 거기부터 100개를 가져오도록 처리하였습니다.
쿼리 성능을 테스트하기 위해서 위 kaggle 데이터에서 조회를 해보았습니다.
SELECT large.*
FROM large_not_partition as large
JOIN (
SELECT lp.id
FROM large_not_partition as lp
where lp.id > 50000000
ORDER BY lp.id
LIMIT 100
) as temp on temp.id = large.id
where large.hs = '204' and large.custom = '400';

(다양한 방법을 테스트하기 위해서 여러 인덱스 후보가 있지만, 옵티마이저는 Primary 인덱스를 선택하여 조회했습니다. 위에 가정한 내용과 같습니다.)
위 실행 계획을 확인해 보니, 인덱스 레인지 스캔을 통해서 PK 값을 찾은 것을 확인할 수 있습니다. 그리고 PK 값을 통해서 원하는 데이터를 조회하였습니다.
실험으로 확인한 결과를 실제 쿼리에 적용하면 아래와 같습니다.
SELECT *
FROM outbox as o
JOIN (
SELECT id
FROM outbox
WHERE id > #{_skiprows}
ORDER BY id
LIMIT #{_pagesize}
) as temp on temp.id = o.id
WHERE aggregate_type = 'com.rollingpaper.ggeujeogggeujeog.user.domain.User' and deleted = 0
비용문제로 테스트 서버에 많은 회원을 생성한 뒤, 조회 성능과 메일 전송 서비스 속도를 테스트하지 못하였습니다. 최대한 실험 조건을 실제 쿼리와 유사하게 만들도록 노력하였고, 이를 적용하였습니다.
4. 과연 이렇게 구현할 필요성이 있을까?
근본적으로 '장기 보관할 필요가 없는 데이터를 굳이 계속 쌓아둘 필요가 있는가?'를 고민하면 위와 같은 문제가 발생하지 않을 것이라 생각합니다. 예를 들어 기간별로 '파티셔닝'을 적용해 각 파티션마다 조회하고 기간이 지난 파티션을 삭제하면 많은 양의 데이터가 쌓이는 것을 방지할 수 있을 겁니다.
하지만 이를 위해서는 테이블 구조를 고려하고 파티셔닝을 적용해야 하기 때문에 보다 빠른 방법으로 개선할 수 있는 쿼리를 수정하였습니다.
참고자료
https://jojoldu.tistory.com/476
https://jojoldu.tistory.com/529?category=637935
https://jojoldu.tistory.com/336
https://jeong-pro.tistory.com/244
https://mybatis.org/spring/ko/batch.html
https://tecoble.techcourse.co.kr/post/2021-10-12-covering-index/
https://use-the-index-luke.com/no-offset
백은빈, 이성욱 저, Real MySQL 1, 2권 개발자와 DBA를 위한 MySQL 실전 가이드, (위키북스, 2021)
'프로젝트 > 끄적끄적' 카테고리의 다른 글
| 비동기 처리를 위한 transactional outbox pattern 적용 (0) | 2023.01.05 |
|---|---|
| 비밀번호 해시 함수 고민과 선택 (0) | 2022.09.25 |
| Scale-Up과 Scale-Out 각 장단점은 무엇일까? (Session Storage, 세션 불일치) (0) | 2022.09.22 |
| Jedis vs Lettuce 둘은 어떤 차이가 있을까? (POSIX - Select, File Descriptor) (0) | 2022.09.20 |



